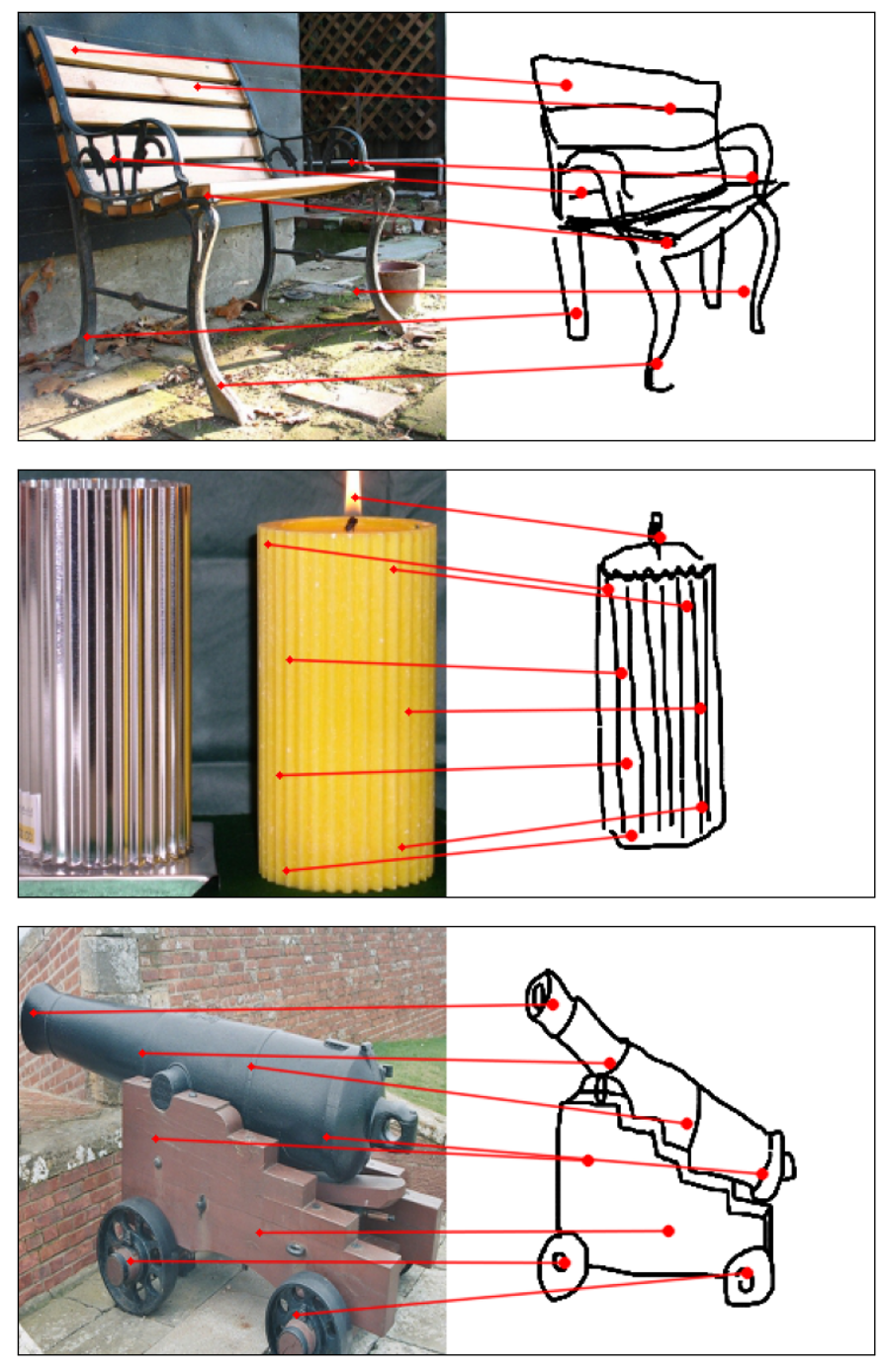
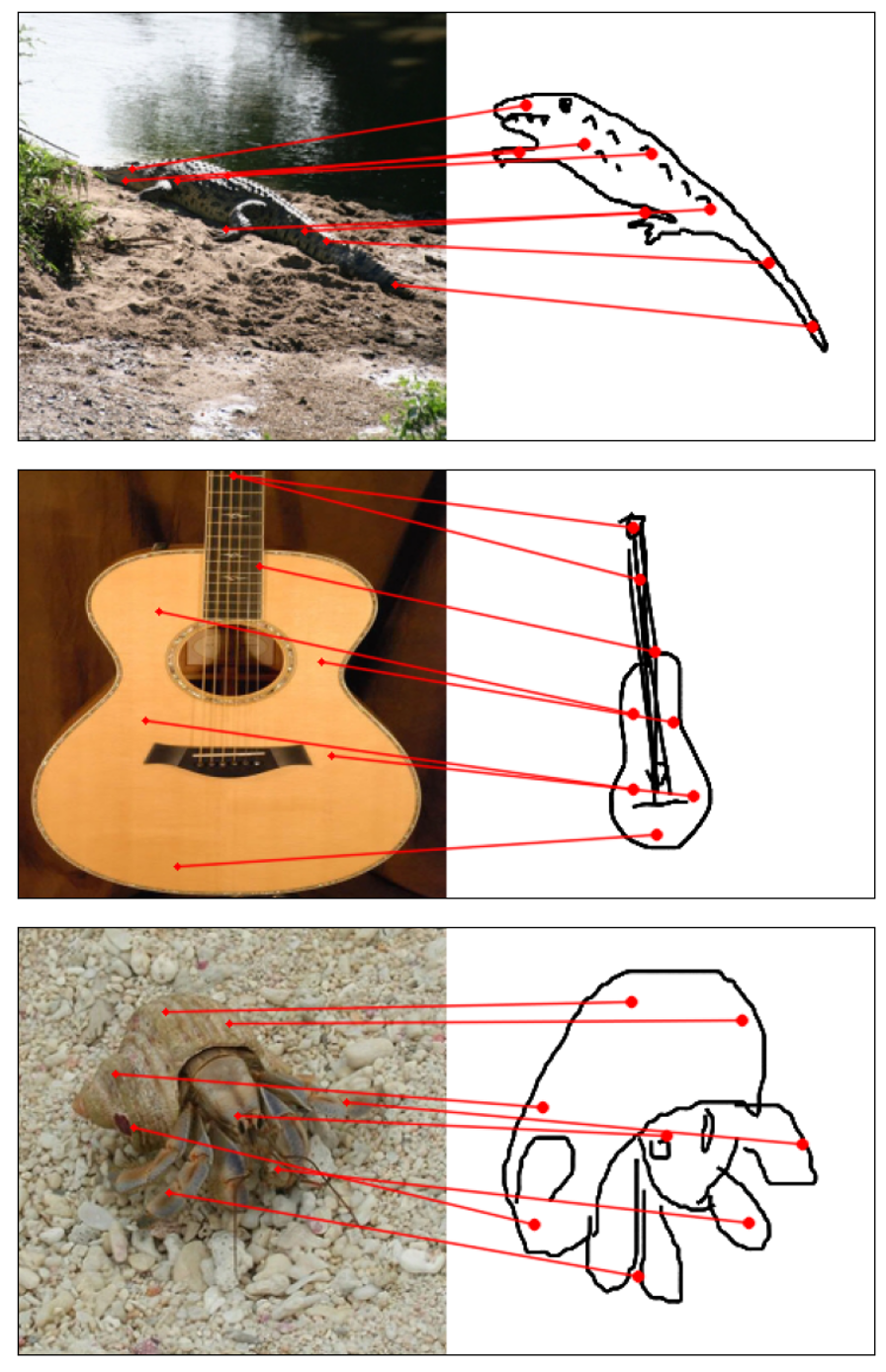
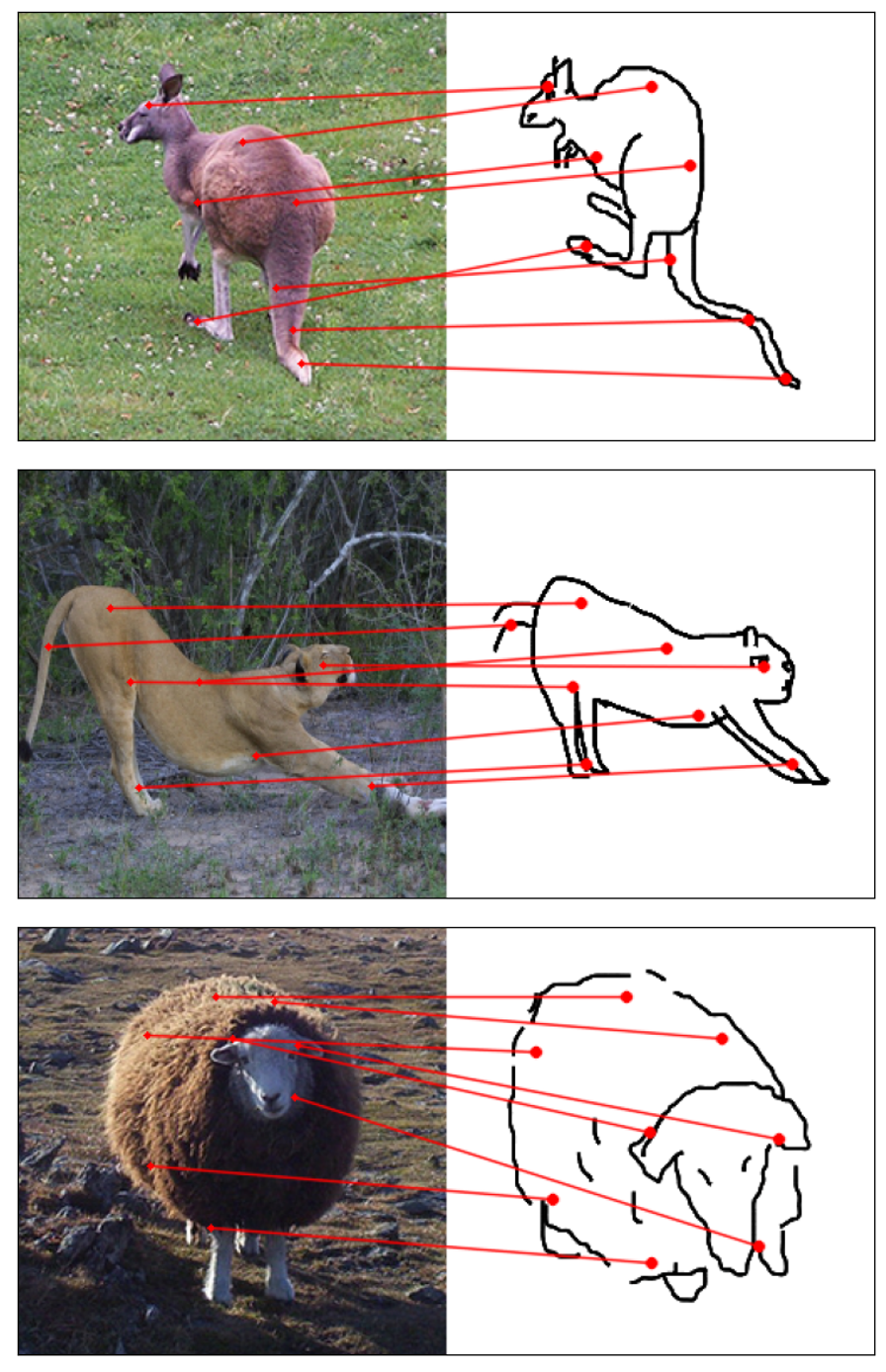
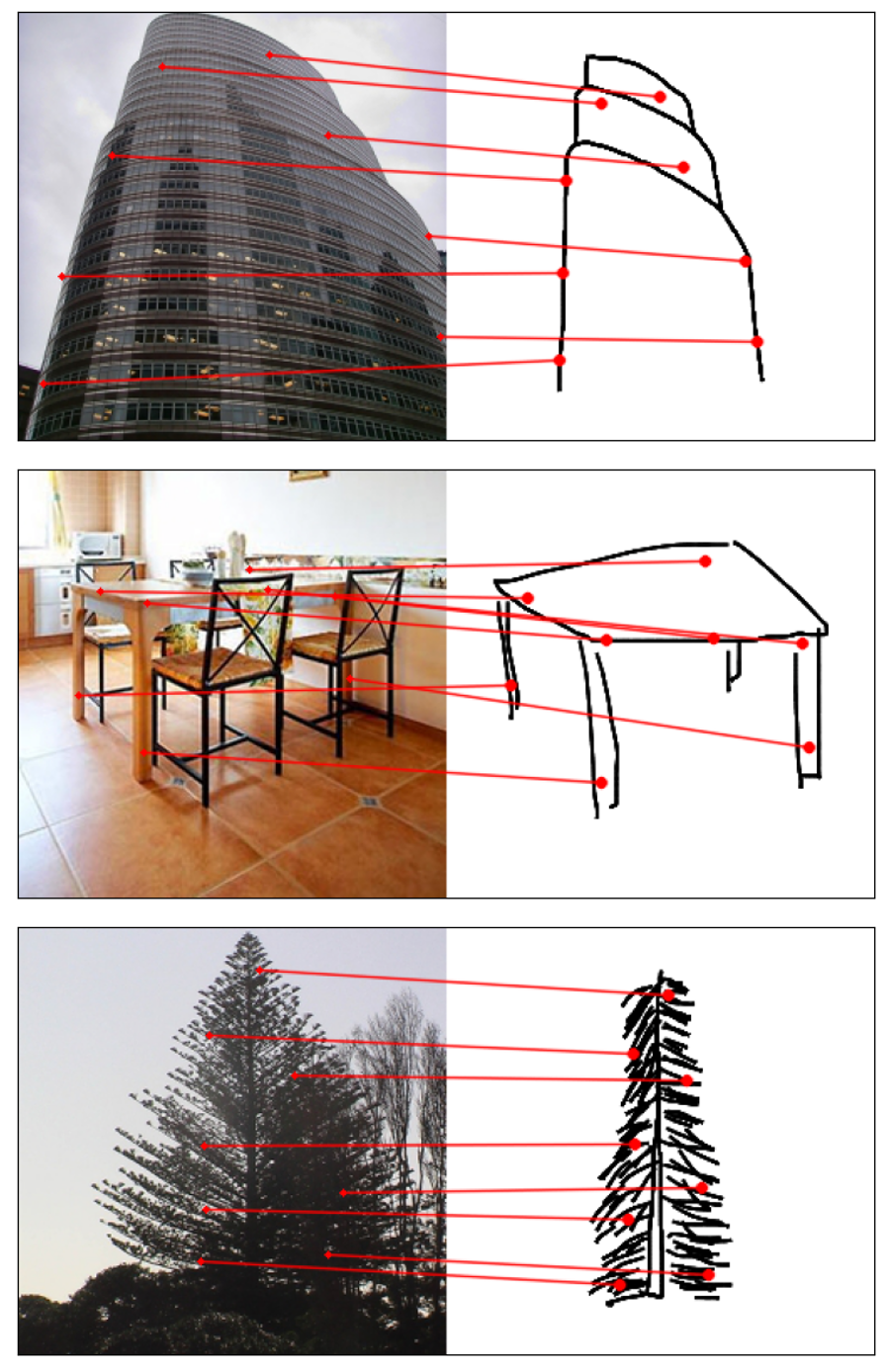
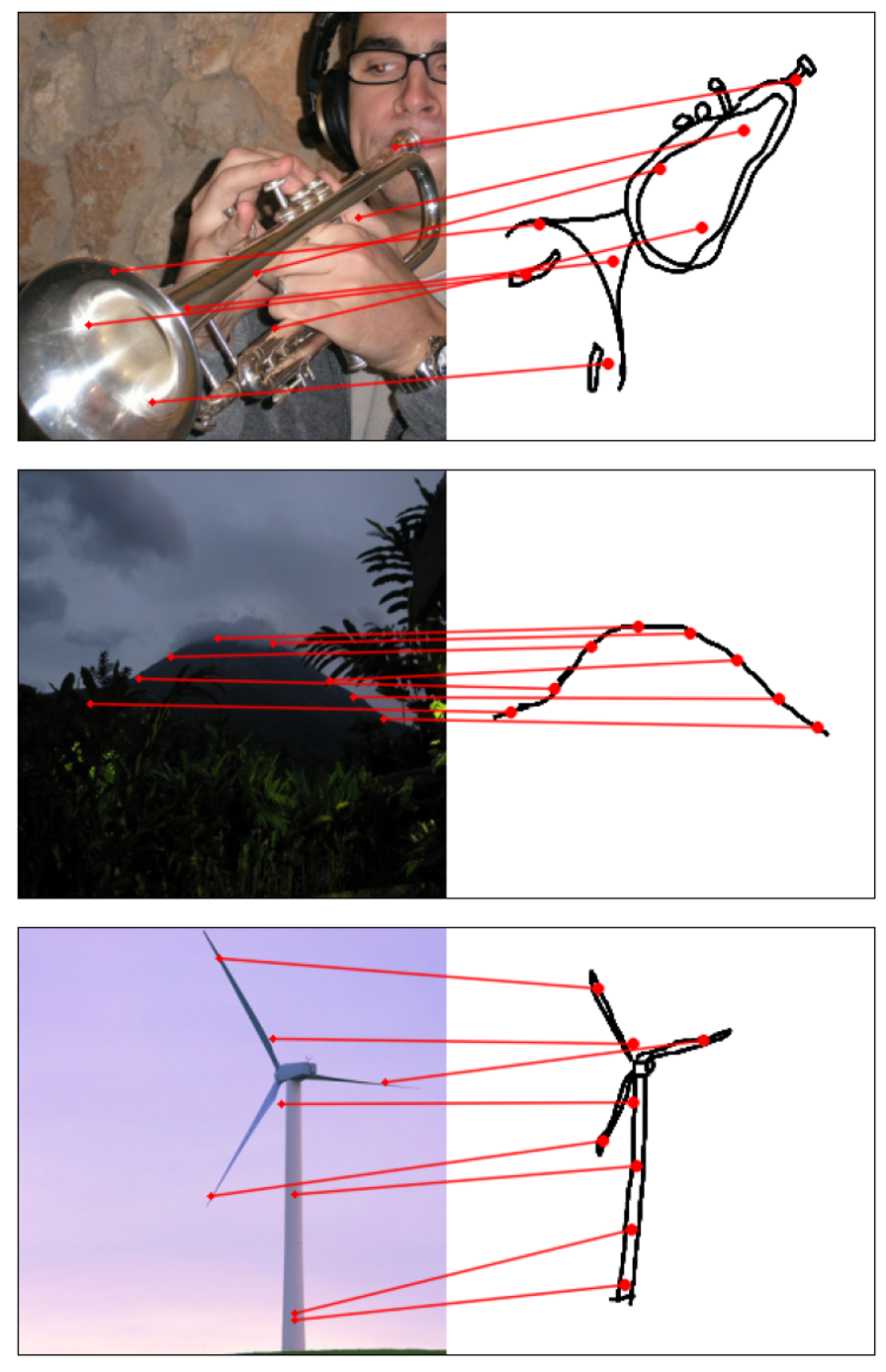
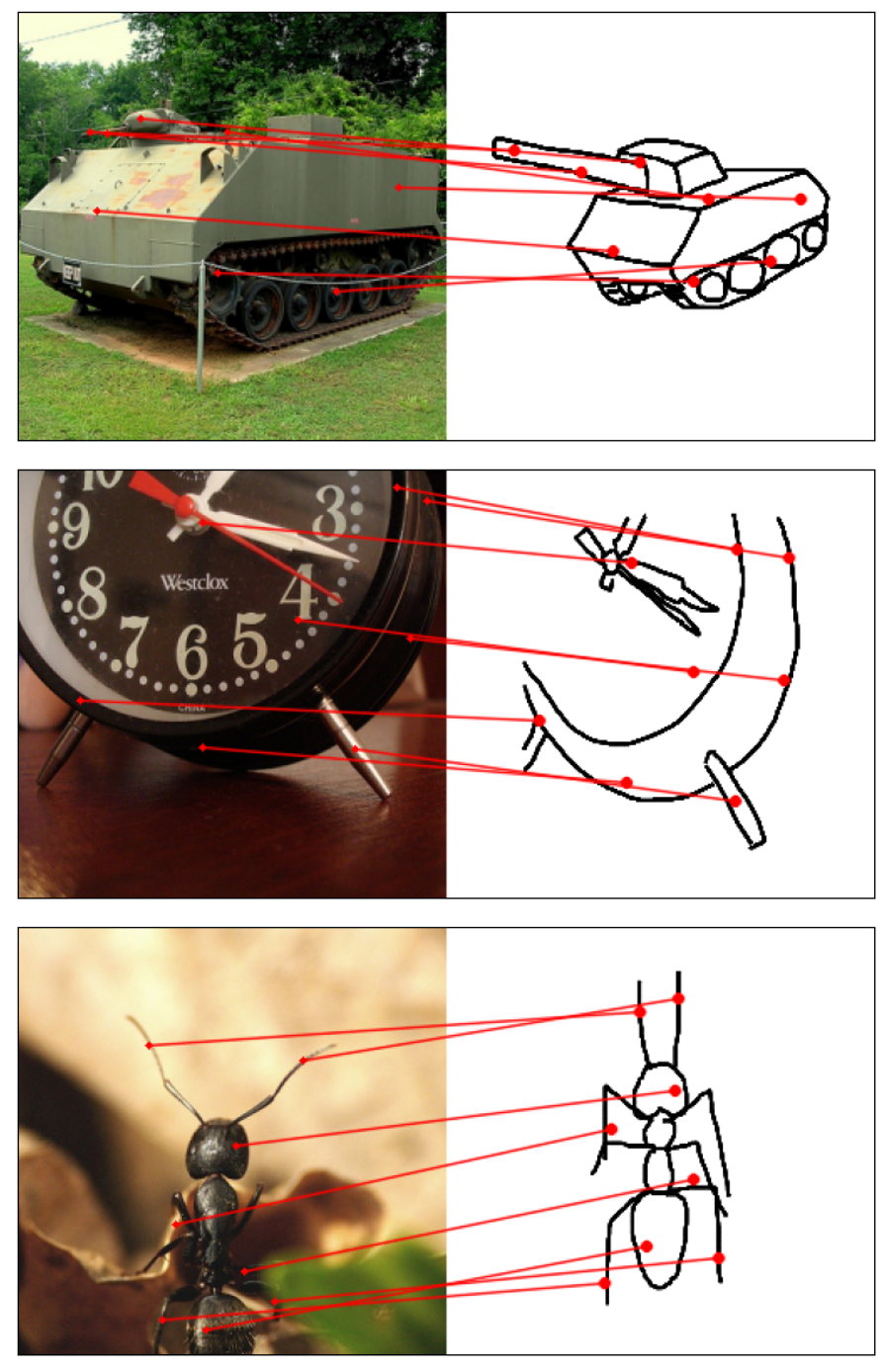
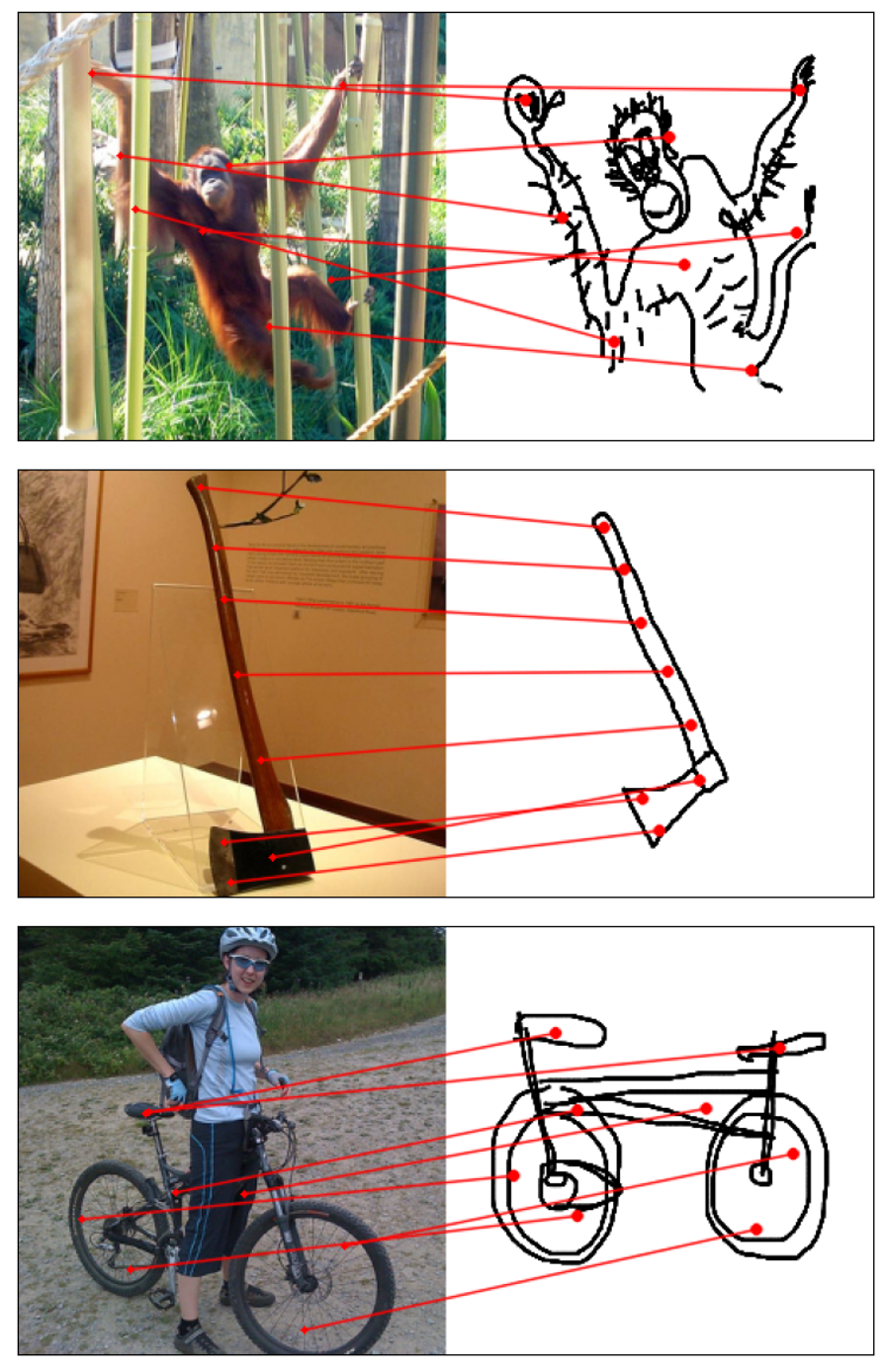
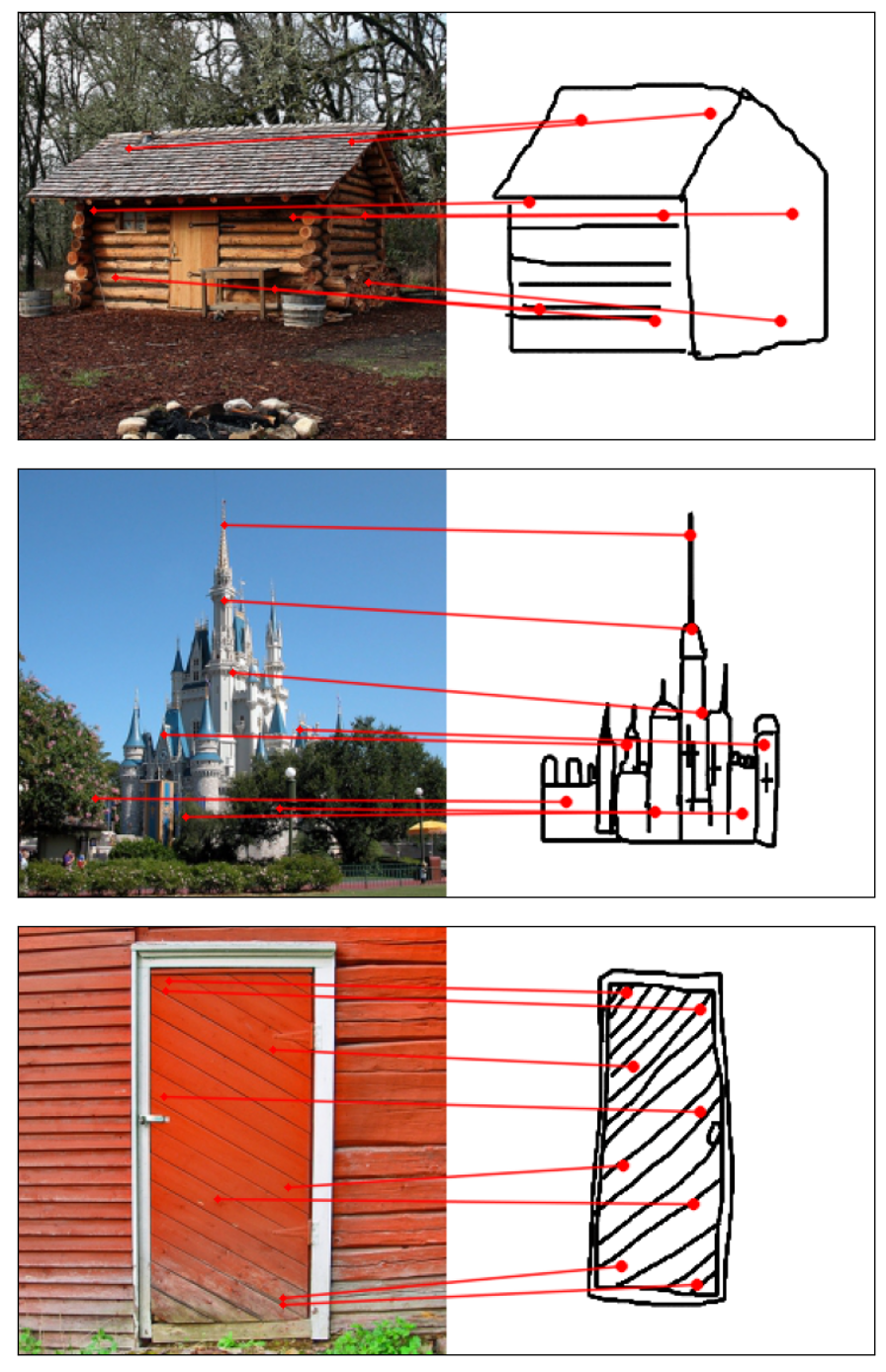
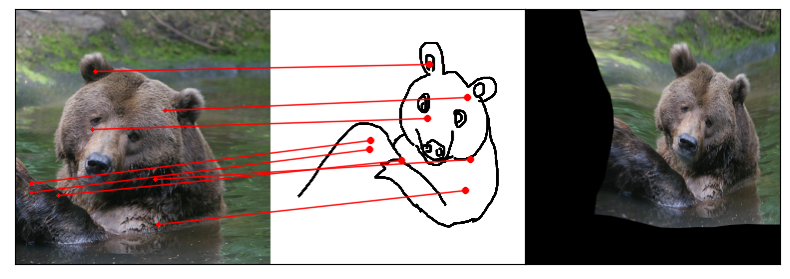
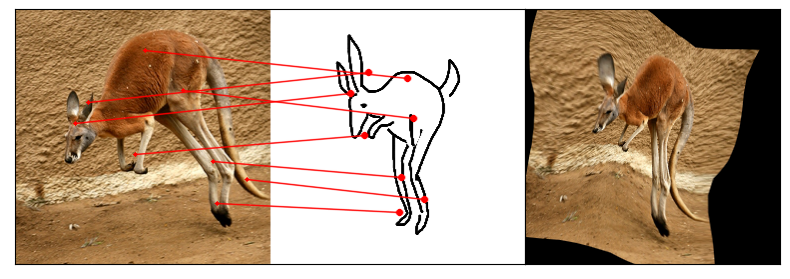
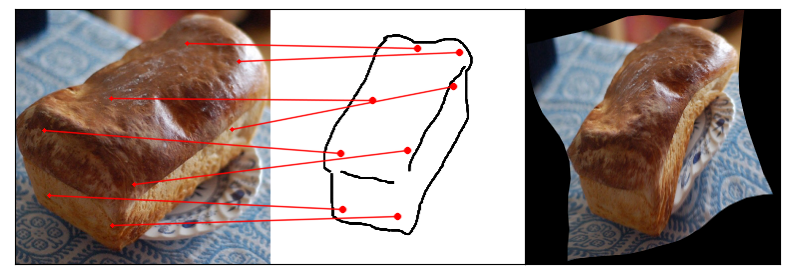
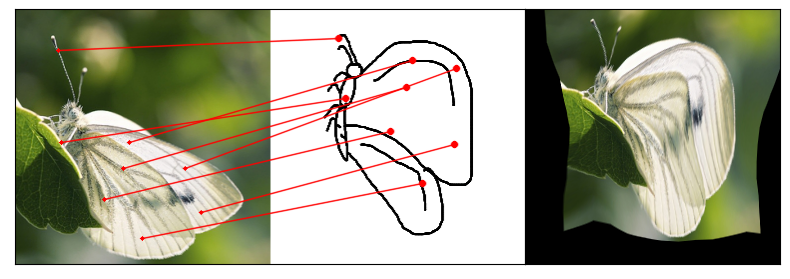
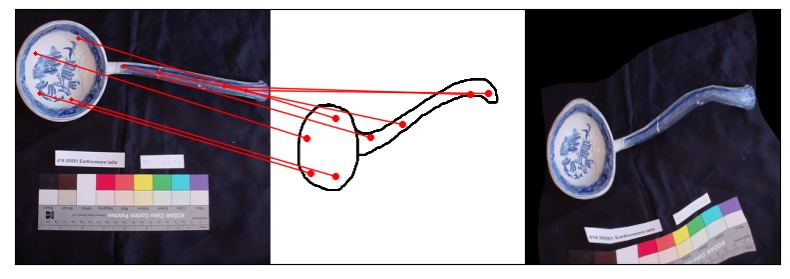
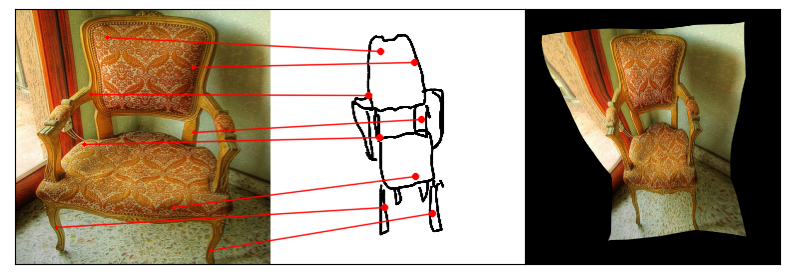
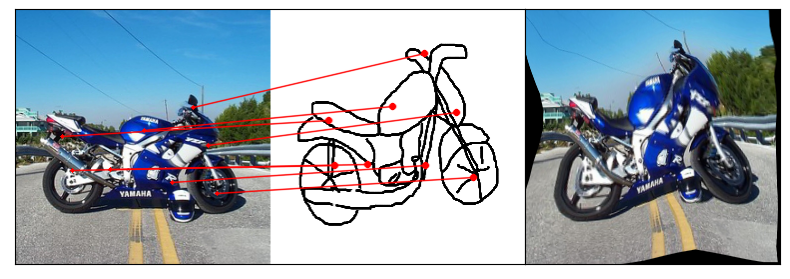
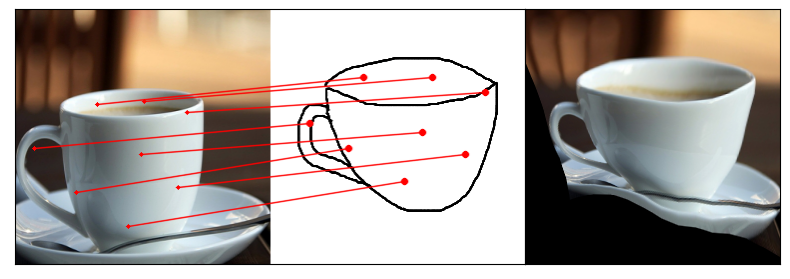
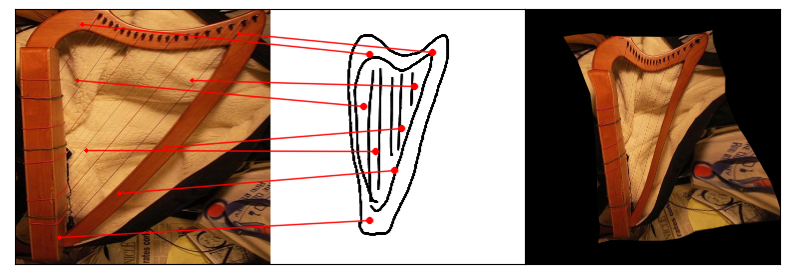
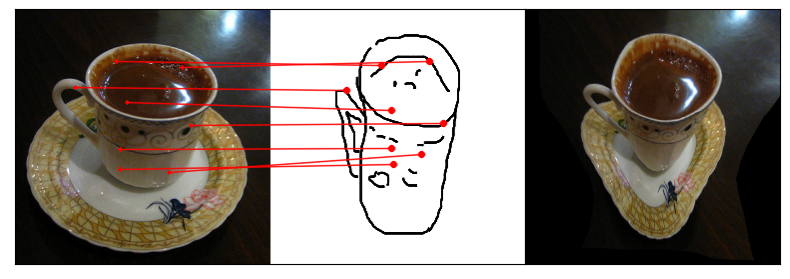
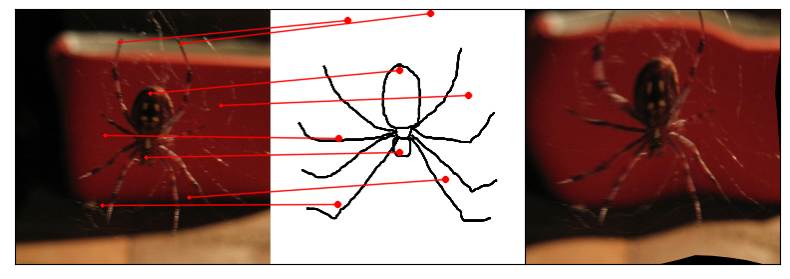
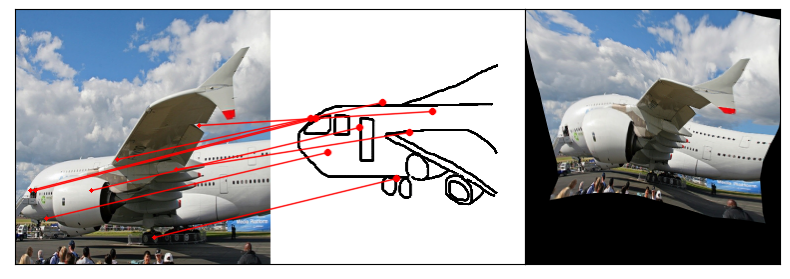
Humans effortlessly grasp the connection between sketches and real-world objects, even when these sketches are far from
realistic. Moreover, human sketch understanding goes beyond categorization - critically, it also entails understanding how
individual elements within a sketch correspond to parts of the physical world it represents.
What are the computational ingredients needed to support this ability?
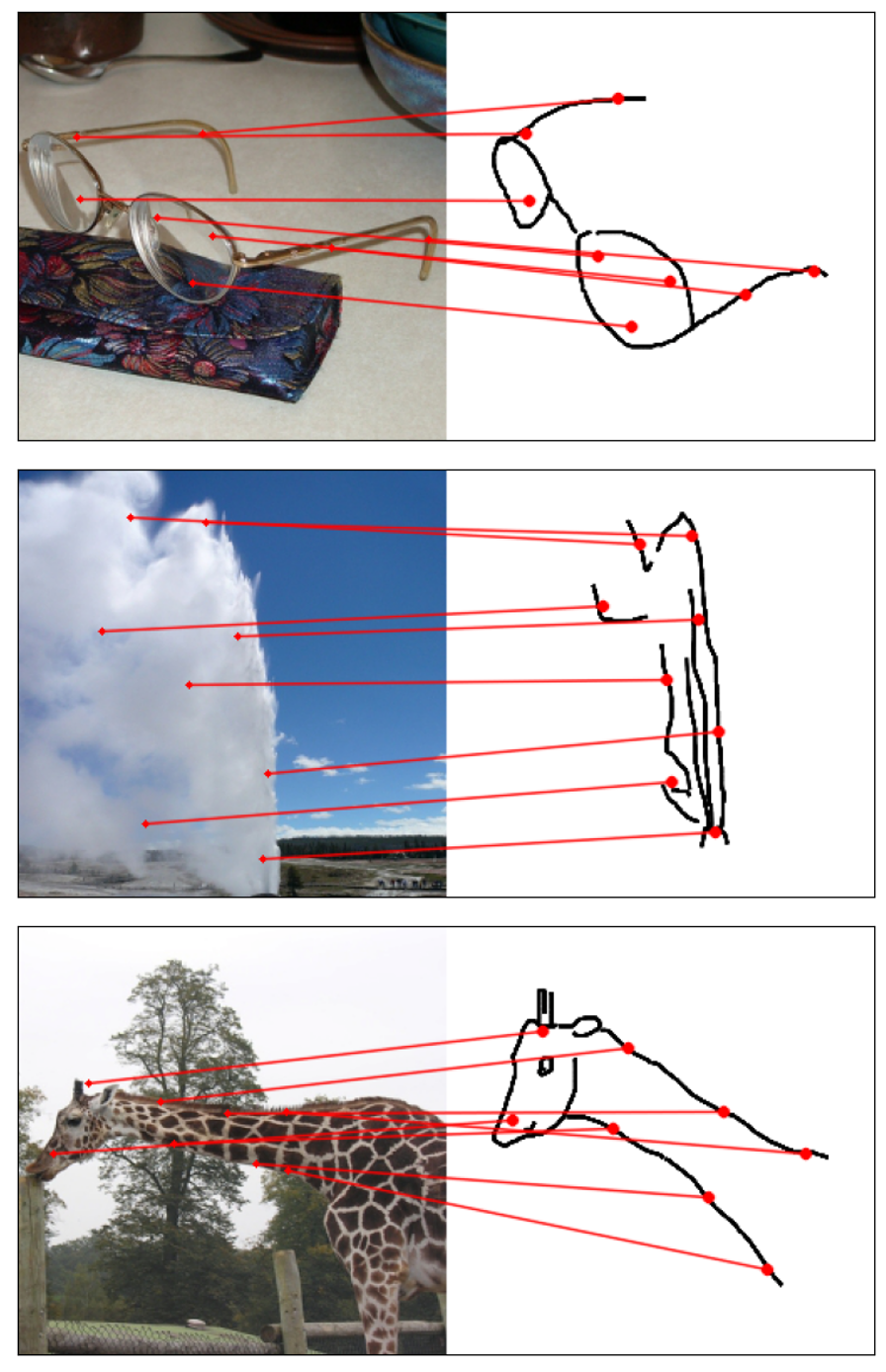
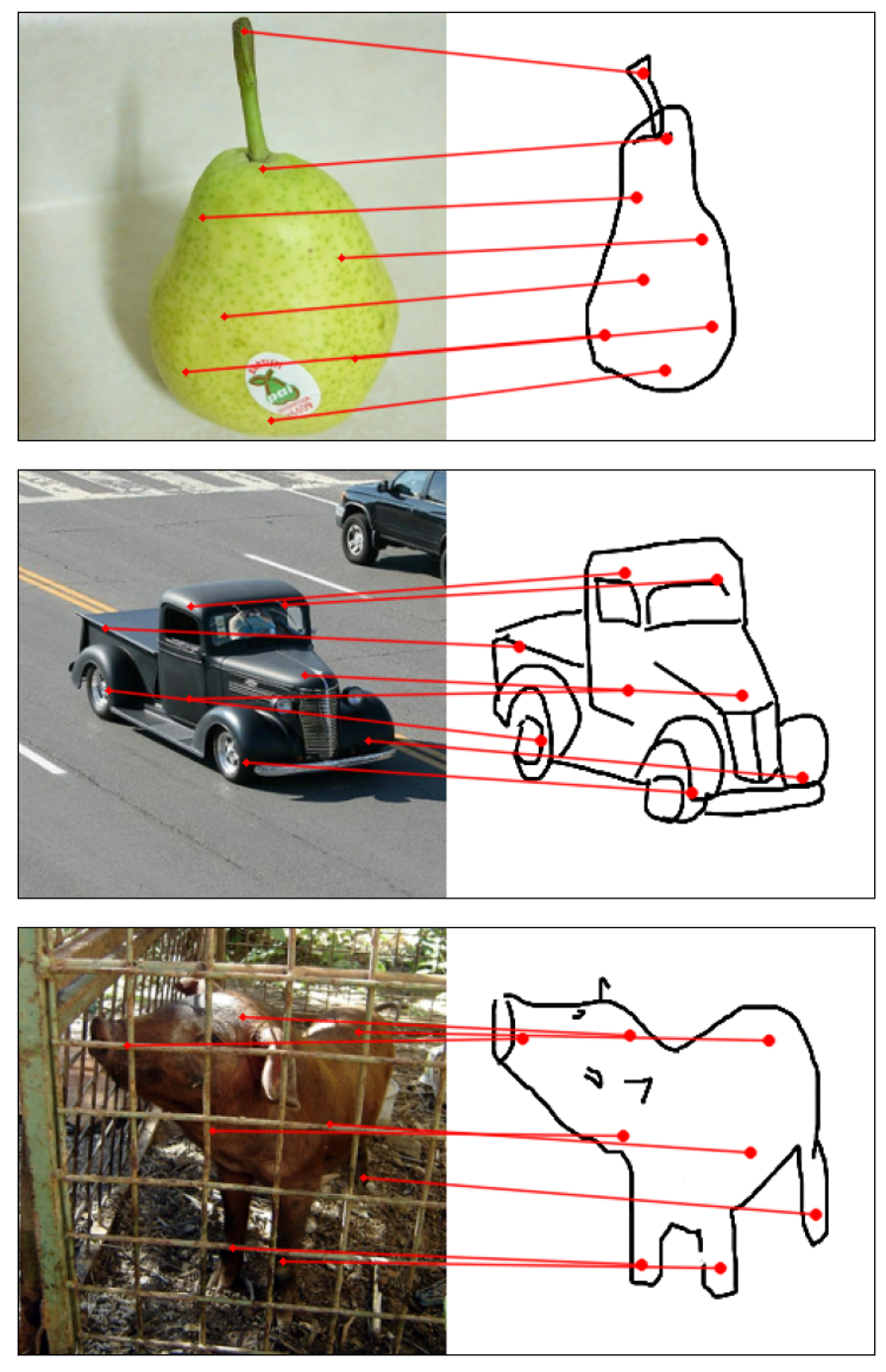
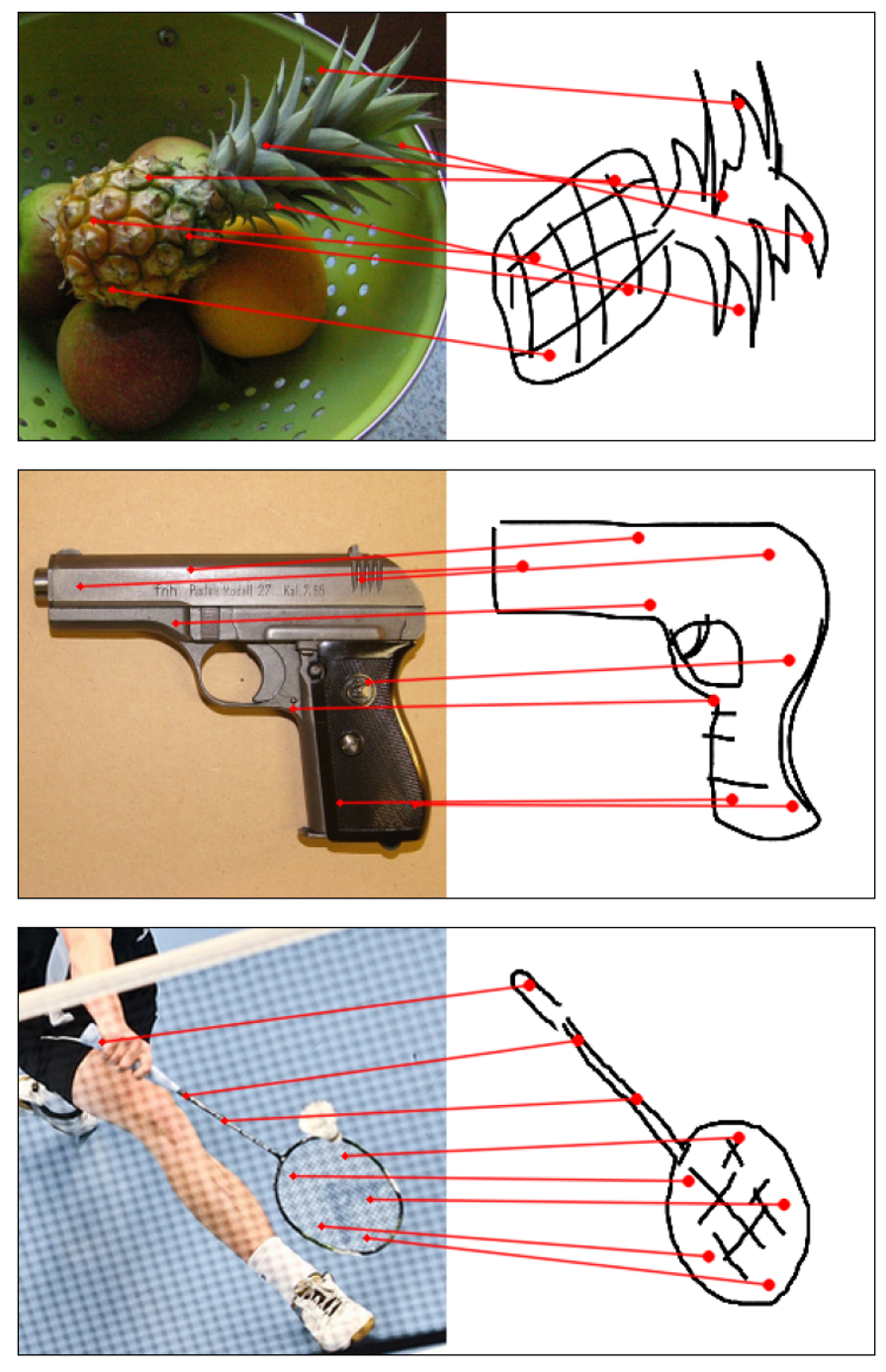
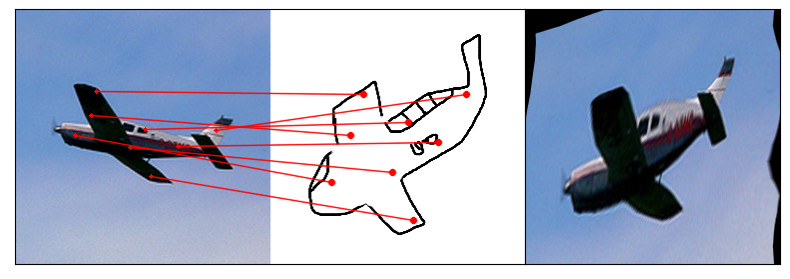
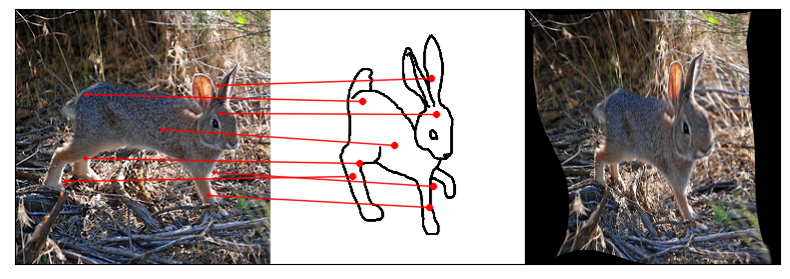
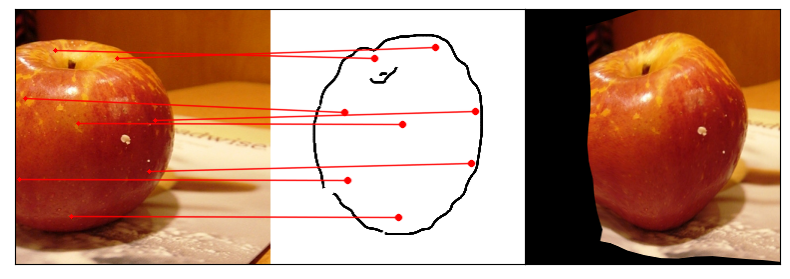
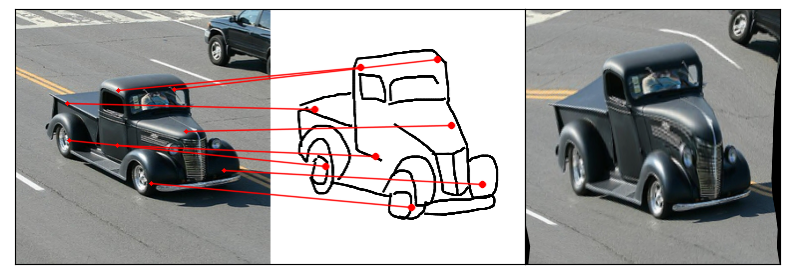
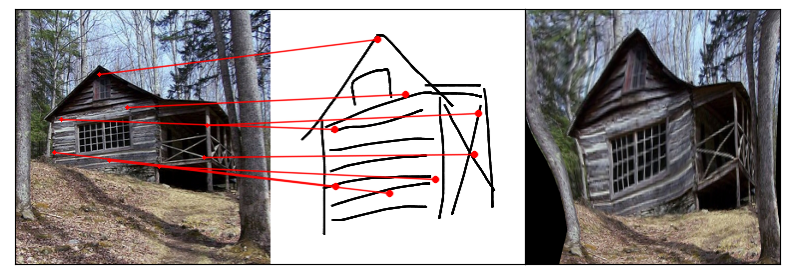
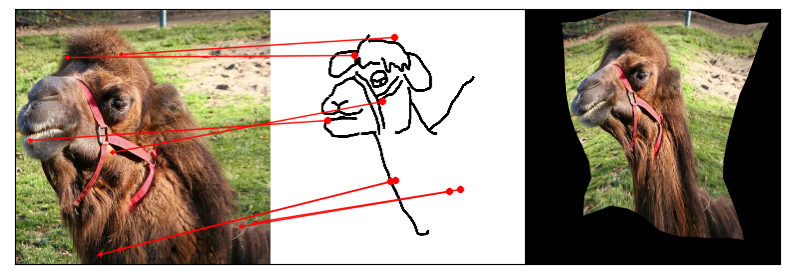
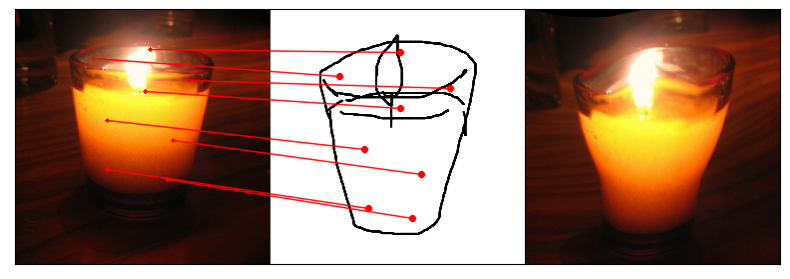
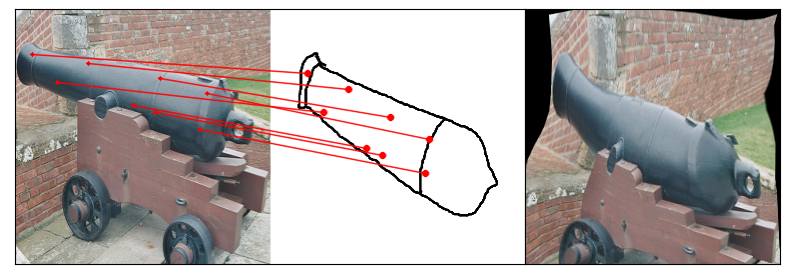
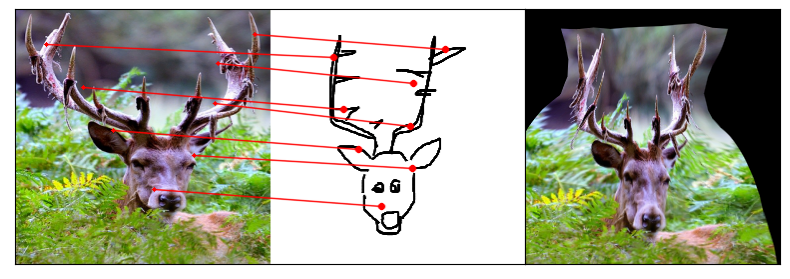
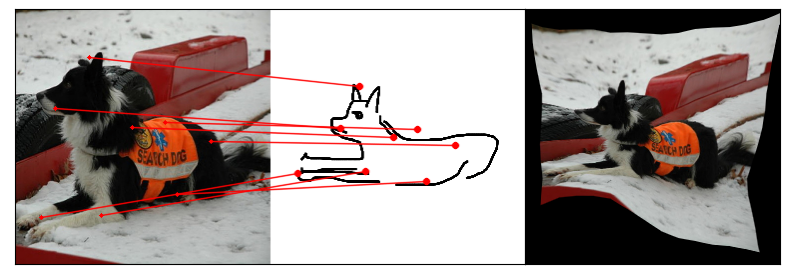
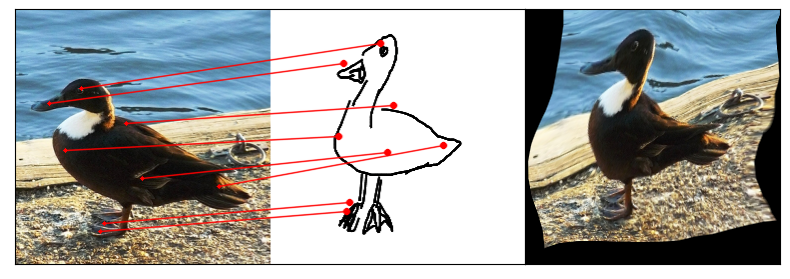
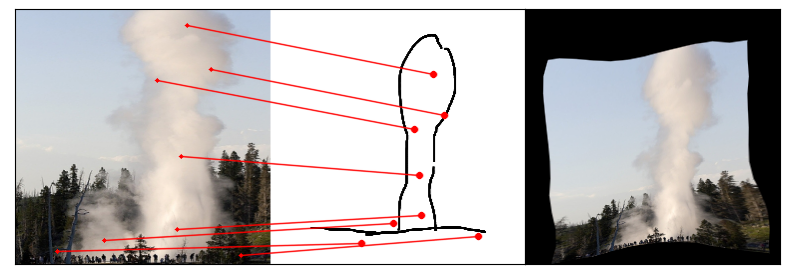
Towards answering this question, we make two contributions: first, we introduce a new sketch-photo correspondence
benchmark, PSC6K, containing 150K annotations of 6250 sketch-photo pairs across 125 object categories,
augmenting the existing Sketchy dataset with fine-grained correspondence metadata.
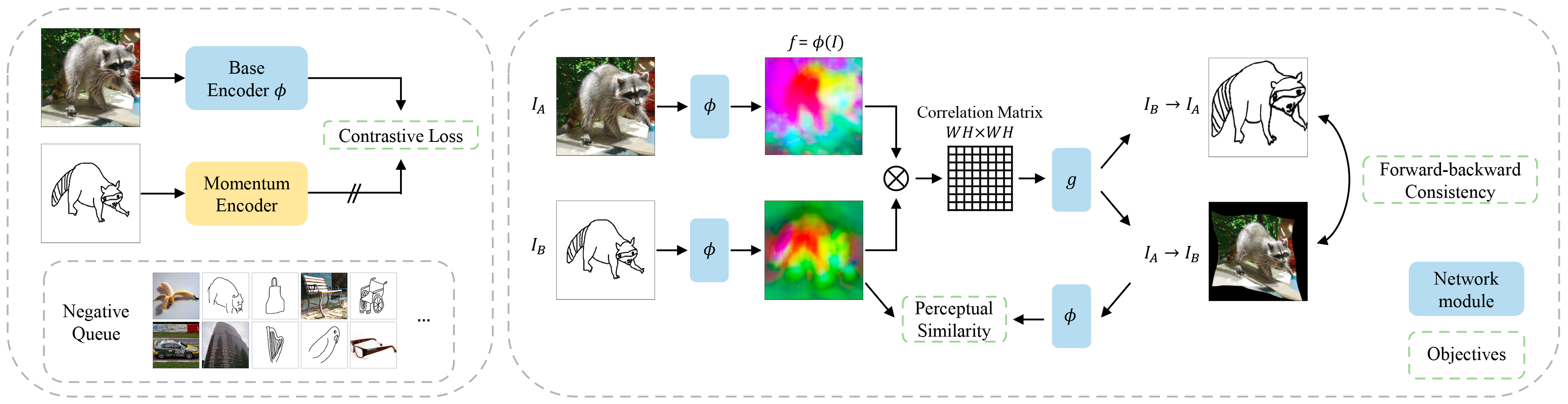
Second, we propose a self-supervised method for learning dense correspondences between sketch-photo pairs, building upon
recent advances in correspondence learning for pairs of photos.
Our model uses a spatial transformer network to estimate the warp flow between latent representations of a sketch and
photo extracted by a contrastive learning-based ConvNet backbone.
We found that this approach outperformed several strong baselines and produced predictions that were quantitatively
consistent with other warp-based methods.
However, our benchmark also revealed systematic differences between predictions of the suite of models we tested and
those of humans.
Taken together, our work suggests a promising path towards developing artificial systems that achieve more human-like
understanding of visual images at different levels of abstraction.